Intro to Regular Expressions

Introduction
Being a Linux user and not coming across Regular Expressions or regex is next to impossible. I kept seeing the cryptic little set of characters everywhere and the people who could use it looked like ninjas to me. They are everywhere text editor's, JavaScript, Python, JAVA , Bash……and the list goes on.

XKCD Regex Comic
What Exactly is a Regular Expression?
A regular expression is a string containing a combination of normal characters and special meta-characters or meta-sequences. The normal characters match themselves. Meta-characters and meta-sequences are characters or sequences of characters that represent ideas such as quantity, locations,or types of characters.
Literals (literally match this)
Something that we normally do while searching for text matches. Character by character matching is done.
Sample Text:
hello world
With the below regex you would match literals since there are no special or meta-characters.
hello
Matches the following characters in source string.
hello world
Meta-characters
Single Character (what to match?):
| Option | Description |
|---|---|
| . | anything |
| \d | digit in 0123456789 |
| \D | non-digit |
| \w | “word” letter digits and _ |
| \W | non-word |
| (a single space) | space |
| \t | tab |
| \r | return |
| \n | newline |
| \s | whitespace ( (a single space), \t, \r, \n ) |
| \S | non-whitespace |
Quantifiers (How many occurence to match?)
| Option | Description |
|---|---|
| X* | Zero or more occurence of X |
| X+ | One or more occurence of X |
| X* | Exactly m instances of X |
| X{m} | One or more instances occurence of X |
| X{m,} | Atleast m instances of X |
| X{m,n} | between m and n instances (inclusive) of X |
+Tis invalidT+means one or more occurrence of the character Tu?means check for 0 or 1 occurrence of u in the string?uis invalid
Position (where?)
| Option | Description |
|---|---|
| \b | Word Boundaires as defined as any edge between \w and \W |
| \B | non-word-boundaries |
| ^ | the beginning of the line |
| $ | the end of the line |
Practising the what, How many and where of regular expressions
Now that we are done with the absolute basics of regular expressions. Whenever writing a regular expression ask yourself what are the “What”, “How many”, and “Where” of the regular expression
The best way to learn regular expression is through Trial and Error.

Regex by Trial and Error
To follow along open up a test regex matching tool in your text editor or Online regex matching tools
Scenario 1:
Matching the word cat
-
what to match : ‘cat’
-
How many : None,Since we are doing literal matching with no repetitions (we want to match cat not catcat).
-
Where : ‘cat’ that do not belong inside any word and are whole words.
regex : \bcat\b
Specifies a regular expressions that matches the literal cat that comes between world boundaries (word boundaries mark the start or end of a word), without the world boundaries the regex will match all occurrence of ‘cat’ in the text. Always remember there is a cat in catastrophe. And the importance of word boundaries.
Scenario 2:
Match all occurrences of 10 digit phone numbers
- What to match : All numbers \d (for digit match)
- How many : 10 occurrences.
- Where : not needed
Character Classes and Alternations
Character classes (anything in between [ ])
Think of them as the OR operation in programming. We specify in the character class braces any alternations of character that need to be matched.
[ab]means matches foraorbf[au]nmatches forfanandfun
Note: if you specify single character meta-character inside [ ] it loses its special characteristics
But there are characters that have special meaning inside [] braces in regular expressions they are
^ - Anything except what is specified. [^ab] means match anything
except a or b
- - If it is the first character inside the [ ] it is treated as a
literal - but if in between different characters or digits it specifies
a range [a-z] means lowercase characters from a to z and [0-10] means
numbers from 0 to 10.
Alternations ( anything in between ( | ) )
What if we needed to give an or option for a set of character like match
a ’net’ or a ‘com’
we can use (net|com) for multi-character option matching.
Example:
www.facebook.(com|net) matches www.facebook.com and www.facebook.net
Advanced Regular Expressions with Groups and Back References
Groups
Regular expressions can be divided into parts that can be later used for replace and other operations.
$0 is the whole regular expression
$1 is the first part .
$2 is the second part and so on from the left to right.
In the following example we do a search and replace of Last-name , First-name to First-Name Last-name
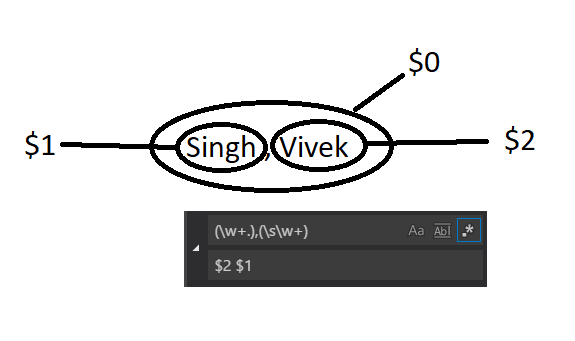
Groups in regular expression
Back References
It is a way of specifying a previous group of regular expression later in the same regular expression using \GroupNo .
Imagine a scenario where we are searching for occurrence of the same word one after.
hello hello ha ha kill kill
we make use of the regex (\w+)\s\1 which uses the \1 to specify the
same pattern as the first group
Reading Regular Expressions
^\w\w\w\S$ - (^)begin with any word character(\w) and then two more
word characters then anything except a space.
^T+\w\w\d$ - (^)begin with one or more (+) occurrence of T followed
by two (\w)word characters then a (\d)digit and then the end.